http://www.cnblogs.com/yank/p/3529395.html
https://www.zhihu.com/question/20112194
http://openresty.org/download/agentzh-nginx-tutorials-zhcn.html

村长博客
在公司业务中的一个用户表达到将近800万条数据,系统后台管理系统有个用户模块做分页处理便于运营查看。但是如果你点到很后面或者最后的页数,你会发现系统执行的很慢,让人难以接受。
打开这个功能的使用的存储过程,做了简单的处理核心代码如下
|
|
可以发现这种写法,当开始行数达到700万行的时候执行时间为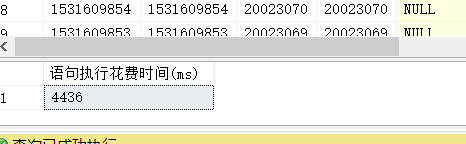
执行一次分页是4秒多,显现这是很慢的。
我们换一种写法,用sqlserver Set Rowcount方法,代码如下:12345678910111213141516171819declare @d datetimeset @d=getdate()declare @begin int = 7000000declare @num int = 20declare @id int declare @moveRecords intdeclare @currentPage int set @currentPage = (@begin+@num-1)/@numset @moveRecords = @currentPage*@num+1Set Rowcount @MoveRecords select @id = idx from member order by idx desc--select @idset rowcount @numSelect * From member Where idx>=@id Order By idx descSet Rowcount 0 select [语句执行花费时间(ms)]=datediff(ms,@d,getdate())
执行时间大概是1.6秒左右,这个分页的方式性能比上一种提高了将近三倍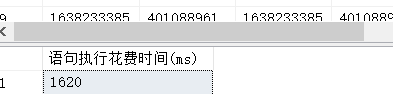
为什么第二种方法执行性能比第一种好呢?因为用Set Rowcount 在返回指定的行数之后就停止处理查询了。而用with t as()的方法需要先查询整个结果集,在去处理分页,所以时间上会消耗比较多。
SET ROWCOUNT 的用法
使 Microsoft® SQL Server™ 在返回指定的行数之后停止处理查询。
语法
SET ROWCOUNT { number | @number_var }
参数
number | @number_var
是在停止给定查询之前要处理的行数(整数)。
注释
建议将当前使用 SET ROWCOUNT 的 DELETE、INSERT 和 UPDATE 语句重新编写为使用 TOP 语法。有关更多信息,请参见 DELETE、INSERT 或 UPDATE。
对于在远程表和本地及远程分区视图上执行的 INSERT、UPDATE 和 DELETE 语句,忽略 SET ROWCOUNT 选项设置。
若要关闭该选项(以便返回所有的行),请将 SET ROWCOUNT 指定为 0。
说明 设置 SET ROWCOUNT 选项将使大多数 Transact-SQL 语句在已受指定数目的行影响后停止处理。这包括触发器和 INSERT、UPDATE 及 DELETE 等数据修改语句。ROWCOUNT 选项对动态游标无效,但限制键集的行集和不感知游标。使用该选项时应谨慎,它主要与 SELECT 语句一起使用。
当前java领域比较流行的两种框架ssh框架和ssm框架,这两种都是企业开发的MVC框架,是我们java程序员必备的知识能力。MVC,即模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑,数据,界面分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。框架之所以流行,在于其易复用和简化开发,在于其易复用和简化开发,精髓在思想,掌握了核心思想,我们掌握其他类似框架也不会有问题,建议大家有精力的话读一下框架源码,尤其是spring
SSH是struts+spring+hibernate的一个集成框架,是目前比较流行的一种web应用程序开源框架。
集成SSH框架的系统从职责上分为四层:表示层、业务逻辑层、数据持久层和域模块层,以帮助开发人员在短期内搭建结构清晰、可复用性好、维护方便的Web应用程序。其中使用Struts作为系统的整体基础架构,负责MVC的分离,在Struts框架的模型部分,控制业务跳转,利用Hibernate框架对持久层提供支持,Spring做管理,管理struts和hibernate。具体做法是:用面向对象的分析方法根据需求提出一些模型,将这些模型实现为基本的Java对象,然后编写基本的DAO(Data Access Objects)接口,并给出Hibernate的DAO实现,采用Hibernate架构实现的DAO类来实现Java类与数据库之间的转换和访问,最后由Spring做管理,管理struts和hibernate。
相信互联网已经越来越成为人们生活中不可或缺的一部分。Ajax,flex等等富客户端的应用使得人们越加“幸福”地体验着许多原先只能在C/S实 现的功能。
比如Google机会已经把最基本的office应用都搬到了互联网上。当然便利的同时毫无疑问的也使页面的速度越来越慢。自己是做前端开发的,在性能方面,根据Yahoo的调查,后台只占5%,而前端高达95%之多,其中有88%的东西是可以优化的。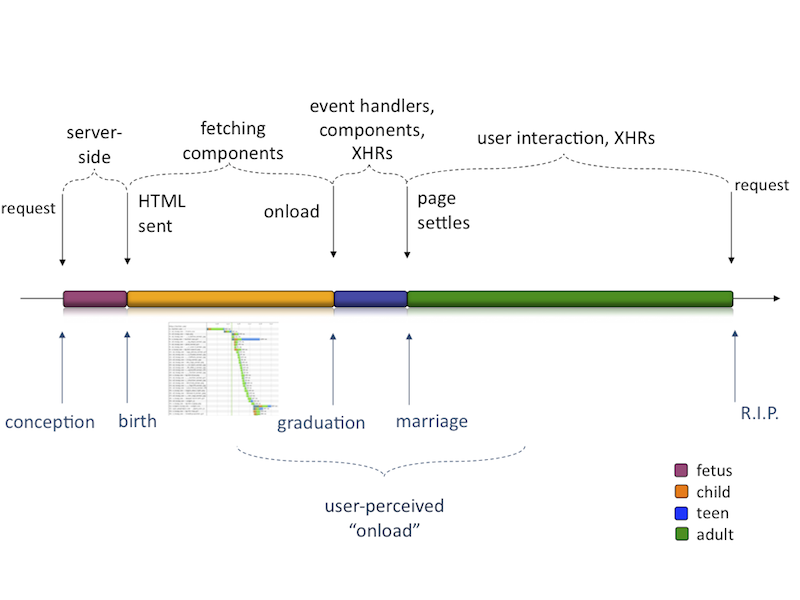
以上是一张web2.0页面的生命周期图。工程师很形象地讲它分成了“怀孕,出生,毕业,结婚”四个阶段。如果在我们点击网页链接的时候能够意识到 这个过程而不是简单的请求-响应的话,我们便可以挖掘出很多细节上可以提升性能的东西。
相信很多人都听过优化网站性能的14条规则。更多的信息可见developer.yahoo.com
http请求是要开销的,想办法减少请求数自然可以提高网页速度。常用的方法,合并css,js(将一个页面中的css和js文件分别合并)以及 Image maps和css sprites等。当然或许将css,js文件拆分多个是因为css结构,共用等方面的考虑。阿里巴巴中文站当时的做法是开发时依然分开开发,然后在后台 对js,css进行合并,这样对于浏览器来说依然是一个请求,但是开发时仍然能还原成多个,方便管理和重复引用。yahoo甚至建议将首页的css和js 直接写在页面文件里面,而不是外部引用。因为首页的访问量太大了,这么做也可以减少两个请求数。而事实上国内的很多门户都是这么做的。
而css sprites是指只用将页面上的背景图合并成一张,然后通过css的background-position属性定义不过的值来取他的背景。淘宝和阿里巴巴中文站目前都是这样做的。有兴趣的可以看下淘宝和阿里巴巴的背景图。
http://www.csssprites.com/这是个工具网站,它可以自动将你上传的图片合并并给出对应的background-position坐标。并将结果以png和gif的格式输出。
说实话,对于CDN这一块自己并不是很了解,简单地讲,通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的 cache服务器内,通过DNS负载均衡的技术,判断用户来源就近访问cache服务器取得所需的内容,杭州的用户访问近杭州服务器上的内容,北京的访问 近北京服务器上的内容。这样可以有效减少数据在网络上传输的时间,提高速度。更详细地内容大家可以参考百度百科上对于CDN的解释。Yahoo!把静态内容分布到CDN减少了用户影响时间20%或更多。
CDN技术示意图: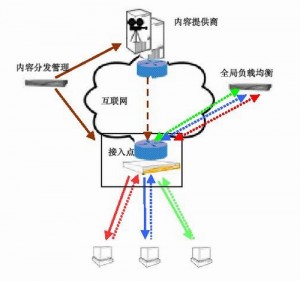
CDN组网示意图: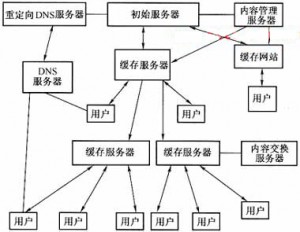
现在越来越多的图片,脚本,css,flash被嵌入到页面中,当我们访问他们的时候势必会做许多次的http请求。其实我们可以通过设置Expires header 来缓存这些文件。Expire其实就是通过header报文来指定特定类型的文件在览器中的缓存时间。大多数的图片,flash在发布后都是不需要经常修改的,做了缓存以后这样浏览器以后就不需要再从服务器下载这些文件而是而直接从缓存中读取,这样再次访问页面的速度会大大加快。一个典型的HTTP 1.1协议返回的头信息:123456789HTTP/1.1 200 OKDate: Fri, 30 Oct 1998 13:19:41 GMTServer: Apache/1.3.3 (Unix)Cache-Control: max-age=3600, must-revalidateExpires: Fri, 30 Oct 1998 14:19:41 GMTLast-Modified: Mon, 29 Jun 1998 02:28:12 GMTETag: “3e86-410-3596fbbc”Content-Length: 1040Content-Type: text/html
其中通过服务器端脚本设置Cache-Control和Expires可以完成。
如,在php中设置30天后过期:1pHeader("Cache-Control: must-revalidate"); $offset = 60 * 60 * 24 * 30; $ExpStr = "Expires: " . gmdate("D, d M Y H:i:s", time() + $offset) . " GMT"; Header($ExpStr)
也可以通过配置服务器本身完成,这些偶就不是很清楚了,呵呵。想了解跟多的朋友可以参考http://www.web-caching.com/
据我了解,目前阿里巴巴中文站的Expires过期时间是30天。不过期间也有过问题,特别是对于脚本过期时间的设置还是应该仔细考虑下,不然相应的脚本功能更新后客户端可能要过很长一段时间才能“感知”到这样的变化。所以,哪些应该缓存,哪些不该缓存还是应该仔细斟酌一番。
Gzip的思想就是把文件先在服务器端进行压缩,然后再传输。这样可以显著减少文件传输的大小。传输完毕后浏览器会 重新对压缩过的内容进行解压缩,并执行。目前的浏览器都能“良好”地支持 gzip。不仅浏览器可以识别,而且各大“爬虫”也同样可以识别,各位seoer可以放下心了。而且gzip的压缩比例非常大,一般压缩率为85%,就是 说服务器端100K的页面可以压缩到25K左右再发送到客户端。具体的Gzip压缩原理大家可以参考csdn上的《gzip压缩算法》 这篇文章。雅虎特别强调, 所有的文本内容都应该被gzip压缩: html (php), js, css, xml, txt…
将css放在页面最上面,这是为什么?因为 ie,firefox等浏览器在css全部传输完全之前不会去渲染任何的东西。理由诚如小马哥说得那样很简单。css,全称Cascading Style Sheets (层叠样式表单)。层叠即意味这后面的css可以覆盖前面的css,级别高的css可以覆盖级别低的css。在[css之!important] 这篇文章的最下面曾简单地提到过这层级关系,这里我们只需要知道css可以被覆盖的。既然前面的可以被覆盖,浏览器在他完全加载完毕之后再去渲染无疑也是合情合理的很多浏览器下,如IE,把样式表放在页面的底部的问题在于它禁止了网页内容的顺序显示。浏览器阻止显示以免重画页面元素,那用户只能看到空白页了。Firefox不会阻止显示,但这意味着当样式表下载后,有些页面元素可能需要重画,这导致闪烁问题。所以我们应该尽快让css加载完毕
将脚本放在页面最下面的目的有那么两点:
1、 因为防止script脚本的执行阻塞页面的下载。在页面loading的过程中,当浏览器读到js执行语句的时候一定会把它全部解释完毕后在会接下来读下 面的内容。不信你可以写一个js死循环看看页面下面的东西还会不会出来。(setTimeout 和 setInterval的执行有点类似于多线程,在相应的响应时间之前也会继续下面的内容渲染。)浏览器这么做的逻辑是因为js随时可能执 行 location.href或是其他可能完全中断此页面过程的函数,即如此,当然得等他执行完毕之后再加载咯。所以放在页面最后,可以有效减少页面可 视元素的加载时间。
2、脚本引起的第二个问题是它阻塞并行下载数量。HTTP/1.1规范建议浏览器每个主机的并行下载数不超过2个(IE只能为2个,其他浏览器如ff等都是默认设置为2个,不过新出的ie8可以达6个)。因此如果您把图像文件分布到多台机器的话,您可以达到超过2个的并行下载。但是当脚本文件下载时,浏览器不会启动其他的并行下载。
当然对各个网站来说,把脚本都放到页面底部加载的可行性还是值得商榷的。就比如阿里巴巴中文站的页面。很多地方有内联的js,页面的显示严重依赖于此,我承认这和无侵入脚本的理念相差甚远,但是很多“历史遗留问题”却不是那么容易解决的。
表达式的问题就在于它的计算频率要比我们想象的多。不仅仅是在页面显示和缩放时,就是在页面滚动、乃至移动鼠标时都会要重新计算一次。给CSS表达式增加一个计数器可以跟踪表达式的计算频率。在页面中随便移动鼠标都可以轻松达到10000次以上的计算量。另外 CSS Expressions 的兼容性很差,所以 CSS Expressions 能不用就不用。
这点我想还是很容易理解的。不仅从性能优化上会这么做,用代码易于维护的角度看也应该这么做。把css和js写在页面内容可以减少2次请求,但也增 大了页面的大小。如果已经对css和js做了缓存,那也就没有2次多余的http请求了。当然,我在前面中也说过,有些特殊的页面开发人员还是会选择内联 的css和js文件。
在 Internet上域名与IP地址之间是一一对应的,域名(kuqin.com)很好记,但计算机不认识,计算机之间的“相认”还要转成ip地址。在网络 上每台计算机都对应有一个独立的ip地址。在域名和ip地址之间的转换工作称为域名解析,也称DNS查询。一次DNS的解析过程会消耗20-120毫秒的 时间,在dns查询结束之前,浏览器不会下载该域名下的任何东西。所以减少dns查询的时间可以加快页面的加载速度。yahoo的建议一个页面所包含的域 名数尽量控制在2-4个。这就需要对页面整体有一个很好的规划。
压缩js和css的左右很显然,减少页面字节数。容量小页面加载速度自然也就快。而且压缩除了减少体积以外还可以起到一定的保护左右。这点我们做得不错。常用的压缩工具有JsMin、YUI compressor等。另外像http://dean.edwards.name/packer/还给我们提供了一个非常方便的在线压缩工具。你可以在jQuery的网页看到压缩过的js文件和没有压缩过的js文件的容量差别:
当然,压缩带来的一个弊端就是代码的可读性没了。相信很多做前端的朋友都遇到过这个问题:看Google的效果很酷,可是去看他的源代码却是一大堆 挤在一起的字符,连函数名都是替换过的,汗死!自己的代码也这样岂不是对维护非常不方便。所有阿里巴巴中文站目前采用的做法是在js和css发布的时候在 服务器端进行压缩。这样在我们很方便地维护自己的代码。
不久前在ieblog上看到过《Internet Explorer and Connection Limits》这篇文章,比如 当你输入http://www.kuqin.com/ 的时候服务器会自动产生一个301服务器转向 http://www.kuqin.com/ ,你看浏览器的地址栏就能看出来。这种重定向自然也是需要消耗时间的。当然这只是一个例子,发生重定向的原因还有很多,但是不变的是每增加一次重定向就会增加一次web请求,所以因该尽量减少。
这点我想不说也知道,不仅是从性能上考虑,代码规范上看也是这样。但是不得不承认,很多时候我们会因为图一时之快而加上一些或许是重复的代码。或许一个统一的css框架和js框架可以比较好的解决我们的问题。小猪的观点很对,不仅是要做到不重复,更是要做到可重用。
这点我也不懂,呵呵。在inforQ上找到一篇解释得比较详细的说明《使用ETags减少Web应用带宽和负载》,有兴趣的同学可以去看看。
ajax还要去缓存?做ajax请求的时候往往还要增加一个时间戳去避免他缓存。It’s important to remember that “asynchronous” does not imply “instantaneous”.(记住“异步”不是“瞬间”这一点很重要)。记住,即使AJAX是动态产生的而且只对一个用户起作用,他们依然可以被缓存。
这篇文章定义了HTML和CSS的格式和代码规范,旨在提高代码质量和协作效率。
省略图片,样式,脚本以及其他媒体文件URL的协议部分(http:https:),除非文件在两种协议下都不可以用。这种方案称为protocol-relative URL,好处是无论你是使用HTTPS还是HTTP访问页面,浏览器都会以相同的协议请求页面中资源,同时可以节省一部分字节12<!-- Not recommended --><script src="https://www.google.com/js/gweb/analytics/autotrack.js"></script>
|
|
|
|
|
|
一次缩进2个空格,不要使用 tab 或者混合 tab 和空格的缩进。1234<ul> <li>Fantastic <li>Great</ul>
|
|
以下都应该用小写:HTML 元素名称,属性,属性值(除非 text/CDATA),CSS 选择器,属性,属性值。
|
|
|
|
|
|
|
|
结尾空格不仅多余,而且在比较代码时会更麻烦。12<!-- Not recommended --><p>What?_
|
|
在 HTML 中通过 指定编码方式,CSS 中不需要指定,因为默认是 UTF-8。
使用注释来解释代码:包含的模块,功能以及优点。
用 TODO 来标记待办事项,而不是用一些其他的标记,像 @@。12345<!-- TODO: remove optional tags --><ul> <li>Apples</li> <li>Oranges</li></ul>
HTML 文档应使用 HTML5 的文档类型:<!DOCTYPE html>。孤立标签无需封闭自身,
不要写成
。
尽可能使用正确的HTML123<!-- Not recommended --><title>Test</title><article>This is only a test.
|
|
根据使用场景选择正确的 HTML 元素(有时被错误的称为“标签”)。例如,使用 h1 元素创建标题,p 元素创建段落,a 元素创建链接等等。正确的使用 HTML 元素对于可访问性、可重用性以及编码效率都很重要。12<!-- Not recommended --><div onclick="goToRecommendations();">All recommendations</div>
|
|
对于像图片、视频、canvas 动画等多媒体元素,确保提供其他可访问的内容。图片可以使用替代文本(alt),视频和音频可以使用文字版本。12<!-- Not recommended --><img src="spreadsheet.png">
|
|
标记、样式和脚本分离,确保相互耦合最小化。
如果团队中文件和编辑器使用同样的编码方式,就没必要使用实体引用,如 —, ”,☺,除了一些在 HTML 中有特殊含义的字符(如 < 和 &)以及不可见的字符(如空格)。12<!-- Not recommended -->The currency symbol for the Euro is “&eur;”.
|
|
在引用样式表和脚本时,不要指定 type 属性,除非不是 CSS 或 JavaScript。因为 HTML5 中已经默认指定样式变的 type 是 text/css,脚本的type 是 text/javascript。123<!-- Not recommended --><link rel="stylesheet" href="//www.google.com/css/maia.css" type="text/css">
|
|
|
|
|
|
属性值用双引号。12<!-- Not recommended --><a class='maia-button maia-button-secondary'>Sign in</a>
|
|
|
|
|
|
id 和 class 应该尽量简短,同时要容易理解。1/* Not recommended */#navigation {}.atr {}
|
|
除非需要,否则不要在 id 或 class 前加元素名。12/* Not recommended */ul#example {}div.error {}
|
|
尽量使用 CSS 中可以简写的属性 (如 font),可以提高编码效率以及代码可读性。123456789/* Not recommended */border-top-style: none;font-family: palatino, georgia, serif;font-size: 100%;line-height: 1.6;padding-bottom: 2em;padding-left: 1em;padding-right: 1em;padding-top: 0;
|
|
值为 0 时不用添加单位。12margin: 0;padding: 0;
值在 -1 和 1 之间时,不需要加 0。1font-size: .8em;
|
|
|
|
使用带前缀的命名空间可以防止命名冲突,同时提高代码可维护性。1.adw-help {} /* AdWords */#maia-note {} /* Maia */
选择器中使用连字符可以提高可读性。12345/* Not recommended: does not separate the words “demo” and “image” */.demoimage {}/* Not recommended: uses underscore instead of hyphen */.error_status {}
|
|
按照属性首字母顺序书写 CSS 易于阅读和维护,排序时忽略带有浏览器前缀的属性。12345678background: fuchsia;border: 1px solid;-moz-border-radius: 4px;-webkit-border-radius: 4px;border-radius: 4px;color: black;text-align: center;text-indent: 2em;
为了反映层级关系和提高可读性,块级内容都应缩进。12345678@media screen, projection { html { background: #fff; color: #444; }}
每行 CSS 都应以分号结尾。12345/* Not recommended */.test { display: block; height: 100px}
|
|
属性名和值之间都应有一个空格。1234/* Not recommended */h3 { font-weight:bold;}
|
|
|
|
|
|
每个选择器都另起一行。1234/* Not recommended */a:focus, a:active { position: relative; top: 1px;}
|
|
规则之间都用空行隔开。1234567html { background: #fff;}body { margin: auto; width: 50%;}
属性选择器和属性值用单引号,URI 的值不需要引号。123/* Not recommended */@import url("//www.google.com/css/maia.css");html { font-family: "open sans", arial, sans-serif;}
|
|
用注释把 CSS 分成各个部分。123/* Header */#adw-header {}/* Footer */#adw-footer {}/* Gallery */.adw-gallery {}
坚持遵循代码规范。
写代码前先看看周围同事的代码,然后决定代码风格。
代码规范的意义在于提供一个参照物。这里提供了一份全局的规范,但是你也得参照公司内部的规范,否则阅读你代码的人会很痛苦。
数据库事务是指作为单个逻辑工作单元的一系列操作,要么完全执行,要么完全的不执行。事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据的资源。通过将一组相关操作组合为一个要么全部成功要么全部失败的单元,可以简化错误恢复并使应用程序更加可靠。一个逻辑工作单元要成为事务,必须满足ACID属性,即为原子性,一致性,隔离性,持久性。事务是数据库运行的逻辑工作单元,由DBMS中事务管理子系统负责事务的处理。
事务必须是原子工作单元;对于其数据修改,要么全部执行,要么全都不执行。
事务完成时 必须使所有的数据都保持一致的状态
由并发事务所作的修改必须与任何其它并发事务所作的修改隔离。
事务完成之后,它对于系统的影响是永久性的。该修改即使出现致命的系统故障也将一直保持。
1.显示事务:也称为用户定义或用户指定的事务,即可以显式地定义启动和结束的事务。分布式事务属于显示事务
2.自动提交事务:这是sqlserver默认的一种事务模式,每条sql语句都被看成一个事务进行处理。如果一个语句成功地完成,则提交该语句。如果遇到错误,则回滚该语句。例如一个update的sql语句更新两个字段,你不会见过其中一个字段更新成功,而另外一个没更新成功的情况。
3.隐形事务:使用Set IMPLICIT_TRANSACTIONS ON将隐形事务模式打开,不用Begin Transaction开启事务,当一个事务结束,这个模式会自动启用下一个事务,只用Commit Transaction提交事务,Rollback Transaction 回滚事务即可
常用的语句有4个:
Begin Transaction(也可以写成begin tran):标记事务开始。
Commit Transaction(也可以写成commit tran):事务已经成功执行,数据已经处理妥当。
Rollback Transaction(也可以写成rollback tran):数据处理过程中出错,回滚到没有处理之前的数据状态,或回滚到事务内部的保存点。
Save Transaction(也可以写成save tran):事务内部设置的保存点,就是事务可以不全部回滚,只回滚到这里,保证事务内部不出错的前提下。
我比较喜欢括号中的写法
书写事务的基本格式:1234567891011121314151617181920---开启事务begin tran--错误扑捉机制begin try --这里可以写你的要执行事务的逻辑代码块end trybegin catch --捕捉错误的日志 下面这句话是读取sql数据库系统的错误可以记录在自己的日志表里面,也可以其他自定义的日志系统 select Error_number() as ErrorNumber, --错误代码 Error_severity() as ErrorSeverity, --错误严重级别,级别小于10 try catch 捕获不到 Error_state() as ErrorState , --错误状态码 Error_Procedure() as ErrorProcedure , --出现错误的存储过程或触发器的名称。 Error_line() as ErrorLine, --发生错误的行号 Error_message() as ErrorMessage --错误的具体信息 if(@@trancount>0) --全局变量@@trancount,事务开启此值+1,他用来判断是有开启事务 rollback tran ---由于出错,这里回滚到开始end catchif(@@trancount>0)commit tran --提交成功
带save tran事务基本书写格式:
save tran的作用就是可以自己设置你要回滚的地方12345678910111213141516171819202122232425---开启事务begin tran--错误扑捉机制begin try --这里可以写你的要执行事务的逻辑代码块 insert into table0 (one,two,three) values(1,2,3) --加入事务保存点 save tran save0 insert into table1 (one,two,three) values(1,2,3) insert into table2 (one,two,three) values(1,2,3)end trybegin catch --捕捉错误的日志 下面这句话是读取sql数据库系统的错误可以记录在自己的日志表里面,也可以其他自定义的日志系统 select Error_number() as ErrorNumber, --错误代码 Error_severity() as ErrorSeverity, --错误严重级别,级别小于10 try catch 捕获不到 Error_state() as ErrorState , --错误状态码 Error_Procedure() as ErrorProcedure , --出现错误的存储过程或触发器的名称。 Error_line() as ErrorLine, --发生错误的行号 Error_message() as ErrorMessage --错误的具体信息 if(@@trancount>0) --全局变量@@trancount,事务开启此值+1,他用来判断是有开启事务 rollback tran ---由于出错,这里回滚到开始end catchif(@@trancount>0)rollback tran save0 --提交事务 如果第二条插入数据错误 则回滚到第二条数据,此时数据库里面只有一条数据。如果全部成功,则有三条数据
使用set xact_abort的事务
set xact_abort的作用是当set xact_abort设置为on时,如果Transact—SQL语句产生运行时错误,整个事务将终止并回滚。为OFF时,只回滚产生错误的Transact—SQL语句,而事务将继续进行处理。编译错误(如语法错误)不受不受 SET XACT_ABORT 的影响。对于大多数OLE DB提供程序(包括SQL Server),隐形或显式事务中的数据修改语句必须将xact_abort设置为ON。唯一不需要该选项的情况是提供程序支持嵌套事务时。set xact_abort的设置是在执行或运行时设置,而不是分析时设置。
|
|
未完待续…
Hexo支持个性化定制主题,可以根据自己的喜好进行修改,想要更多的主题可以点击这里
我选择用的主题是yilia
在你安装博客根目录下面克隆主题
$ git clone https://github.com/litten/hexo-theme-yilia.git themes/yilia
执行
$ vim _config.yml
将 theme 对应的值进行修改
theme: yilia
接着就自动部署一下:
$ npm install hexo-deployer-git --save
最后发布
$ hexo clean && $ hexo g && $ hexo d
现在主题是更改过来了,但还有许多细节需要处理,比如说你需要修改头像等等。
首先进入到根目录下的 themes\yilia 文件夹
执行
$ vim _config.yml
然后在里面配置你相关的信息
配置完之后回到你的博客根目录
$ npm install hexo-deployer-git --save
$ hexo clean && hexo g && hexo d
这样就完成了你需要的博客模板 是不是很nice
经过在网上查资料 终于搭建好了自己的博客系统,完全通过markdown书写自己的博客简单方便
安装Node,这是必须的。
作用:用来生成静态页面
安装Git(必须)
作用:把本地的hexo内容提交到github上去
申请github(必须)
作用:是用来做博客的远程仓库,域名,服务器之类的。
如何申请guthub仓库就不再赘述。
Node和Git都安装好之后(如何安装Node和Git 以及如何使用git,可以自行学习),首先创建一个文件夹,如blog,用户存放hexo的配置文件,然后进入blog安装Hexo。
执行如下命令安装Hexo:
npm install -g hexo
初始化然后,执行init命令初始化hexo,命令:
hexo init
到这里为止,所有的安装工作已经完成!
生成静态页面
hexo generate(hexo g也可以)
本地启动
启动本地服务,进行文章预览调试,命令:
hexo server
浏览器输入http://localhost:4000 可以访问
建立Repository
建立与你用户名对应的仓库,仓库名必须为【your_user_name.github.io】,固定写法然后建立联系,我的blog之前建立的东西也全部在这里面
有
_config.yml node_modules public source db.json
package.json scaffolds themes
现在我们需要_config.yml文件,来建立关联
用文件编辑器打开_config.yml(我个人喜欢用sublime)
翻到最下面,改成我这样子的
deploy:
type: git
repo: https://github.com/desperadowxh/desperadowxh.github.io.git
branch: master
然后执行命令:
npm install hexo-deployer-git –save
还有一种是用ssh keys协议的 上传的时候就不用输入账号和密码了,可以改成这个样子
deploy:
type: git
repo: git@github.com:desperadowxh/desperadowxh.github.io.git
branch: master
然后执行命令:
npm install hexo-deployer-git –save
然后执行配置命令:
hexo deploy(hexo d)
然后再浏览器中输入 http://desperadowxh.github.io/ 就行了,我的github的账户叫desperadowxh,把这个改成你github的账户名就行了
每次部署的步骤,可以按照以下的来进行
hexo clean
hexo generate(hexo g)
hexo deploy(hexo d)
hexo new”postName” #新建文章
hexo new page”pageName” #新建页面
hexo generate #生成静态页面至public目录
hexo server #开启预览访问端口(默认端口4000,’ctrl + c’关闭server)
hexo deploy #将.deploy目录部署到GitHub
hexo help # 查看帮助
hexo version #查看Hexo的版本
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true