
Java内存模型,内存间的交互操作
Java内存模型
- JCP定义了一种Java内存模型,以前是在JVM规范中,后来独立出来成为JSR-133(Java内存模型和线程规范修订)
- 内存模型:在特定的操作协议下,对特定的内存或高速缓存进行读写访问的过程抽象
- Java内存模型主要关注JVM中把变量值存储到内存和从内存中取出变量值这样的底层细节。Java内存模型示意图:
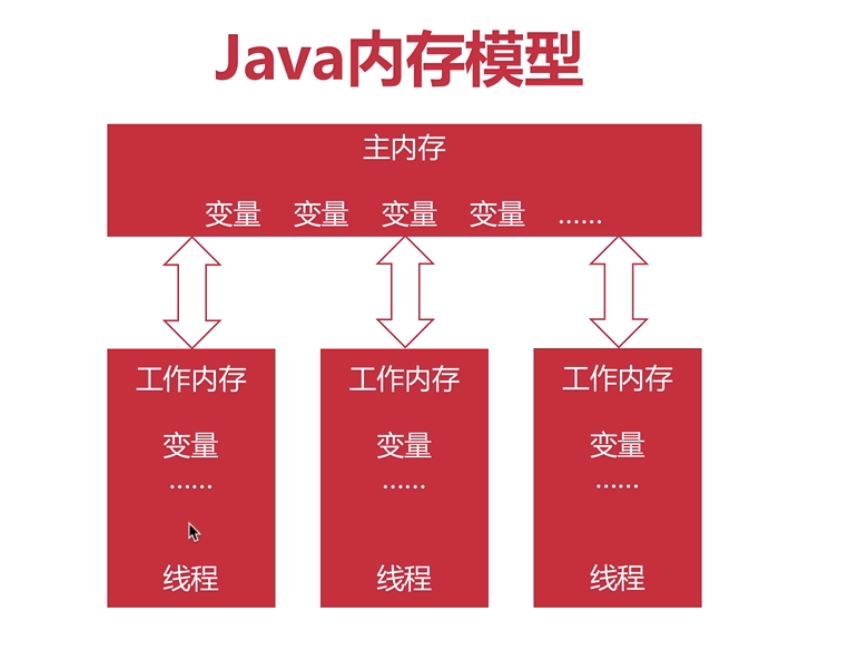
- 所以变量(共享的)都存储在主内存中,每个线程都有自己的工作内存;工作内存中保存该线程使用到的变量的主内存副本拷贝
- 线程对变量的所以操作(读,写)都应该在工作内存中完成
- 不同线程不能互相访问工作内存,交互数据要通过主内存进行

内存间的交互操作
Java内存模型规定了一些操作来实现内存间交互,JVM会保证它们是原子的。具体如下:
- lock:锁定,把变量标识为线程独占,作用于主内存变量。
- unlock:解锁,把锁定的变量释放,别的线程才能使用,作用于主内存变量。
- read:读取,把变量值从主内存读取到工作内存。
- load:载入,把read读取到的值放入工作内存的变量副本中。
- use:使用,把工作内存中一个变量的值传递给执行引擎。
- assgin:赋值,把从执行引擎接收到的值赋给工作内存里面的变量。
- store:存储,把工作内存中一个变量的值传递到主内存中。
- write:写入,把store进来的数据存放如主内存的变量中。
下图为内存间的交互操作过程示意图: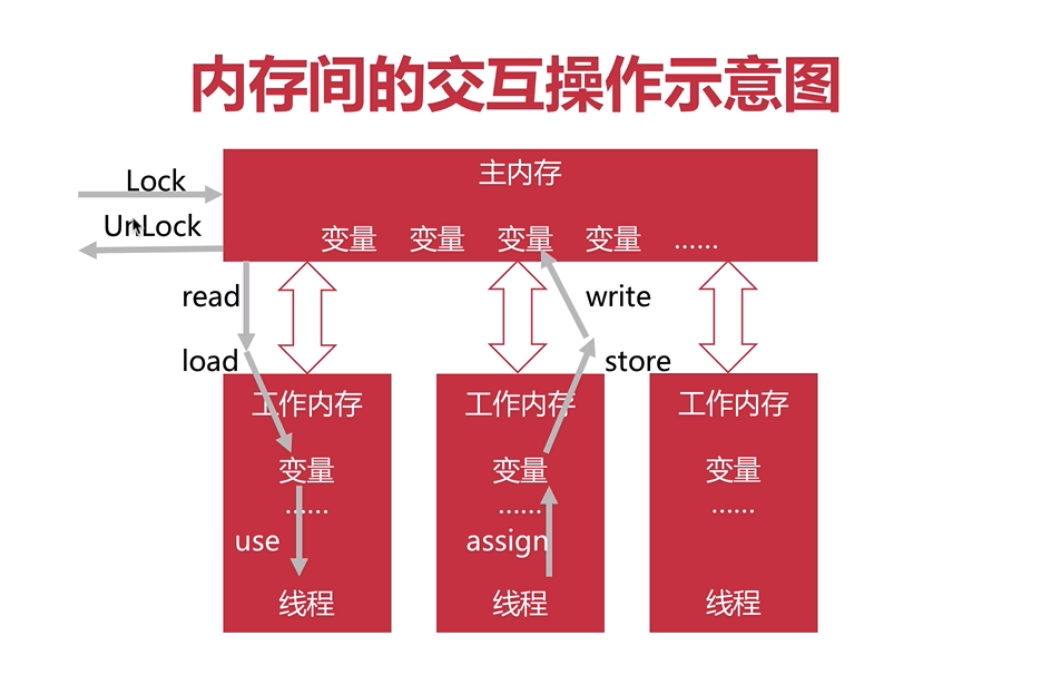
- 1.线程想要使用某个变量,虚拟机需要对主内存某个变量做lock,lock了之后,就标识了这个变量归某个线程独占。
- 2.虚拟机做read操作,将主内存的变量读到工作内存。但是要注意的是,这步操作并没有给到变量上去。
- 3.load操作,将从主内存读到工作内存上的值,真正的赋值给变量。
- 4.工作内存上的变量有了值之后,使用use操作,将变量的值传递到执行引擎,让具体的线程去使用。
- 5.使用完过后,值可能发生变化,执行引擎使用assgin操作把改变的值传回给工作内存内的变
- 6.工作内存的值发生改变之后,我们需要使用store操作,将工作变量的值传递回主内存。同时需要注意,这边的store操作只是把工作内存的值传递到主内存内,并没有赋值到主内存的变量中。
- 7.使用write操作,将主内存的值赋值到主内存的变量中。
- 8.最后线程不使用这个变量了,执行unlock操作。
内存间交互操作的规则
- 不允许read和load,store和write操作之一单独出现,以上两个操作必须按顺序执行,但不保证连续执行,也就是说,read与load之间,store与write之间是可插入其他指令的
- 不允许一个线程丢弃它的最近的assign操作,即变量在工作内存中改变了之后必须把该变化同步回主内存
- 不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存中
- 一个新的变量只能从主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化的变量,也就是对一个变量实施use和store操作之前,必须先执行过了assign和load操作
- 一个变量在同一时刻只允许一条线程对其执行lock操作,但lock操作可以被同一条线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁
- 如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值
- 如果一个变量没有被lock操作锁定,则不允许对它执行unlock操作,也不能unlock一个被其他线程锁定的变量
- 对一个变量执行unlock操作之前,必须先把变量同步回主内存(执行store和write操作)
多线程的可见性,有序性和指令重排,线程安全的处理方法
多线程中的可见性
- 可见性:就是一个线程修改了变量,其他线程可以知道
- 保证可见性的常见方法:volatile,synchronized,final(一旦初始化完成,其他线程就可见)
volatile
- volatile基本上是JVM提供的最轻量级的同步机制,用volatile修饰的变量,对所有的线程可见,即对volatile变量所做的写操作能立即反映到其他线程中
- 用volatile修饰的变量,在多线程环境下仍然是不安全的
- volatile修饰的变量,是禁止指令重排优化的
- 适合使用valatile的场景:
- 指令重排:指的是JVM为了优化,在条件允许的情况下,对指令进行一定的重新排列,直接运行当前能够立即执行的后续指令,避开获取下一条指令所需数据造成的等待。
- 线程内串行语义,不考虑多线程间的语义
- 不是所有的指令都能重排,比如:
- 写后读a=1;b=a;写一个变量之后,再读这个位置
- 写后写a=1;a=2;写一个变量之后,再写这个变量
- 读后写a=b;b=1;读一个变量之后,再写这个变量
以上语句不可重排,但是a=1;b=2;是可以重排的
指令重排的基本规则
- 程序顺序原则:一个线程内保证语义的串行性
- volatile规则:volatile变量的写,先发生于读
- 锁规则:解锁(unlock)必然发生在随后的加锁(lock)前
- 传递性:A先于B,B先于C。那么A必然先于C
- 线程的start方法先于它的每一个动作
- 线程的所有操作先于线程的终结(Thread.join())
- 线程的中断(interrupt())先于被中断线程的代码
- 对象的构造函数执行结束先于finalize()方法
多线程中的有序性
- 在本线程内,操作都是有序的
- 在线程外观察,操作都是无序的,因为存在指令重排或主内存同步延时
Java线程安全的处理方法
- 不可变是线程安全的
- 互斥同步(阻塞同步):synchronized,java.util.concurrent.ReentrantLock.目前这两个方法性能已经差不多了,建议优先选用synchronized,ReentrantLock增加了如下特性:
- 等待可中断:当持有锁的线程长时间不释放锁,正在等待的线程可以选择放弃等待
- 公平锁:多个线程等待同一个锁时,须严格按照申请锁的时间顺序来获得锁
- 锁绑定多个条件:一个ReentrantLock对象可以绑定多个condition对象,而synchronized是针对一个条件的,如果要多个,就得有多个锁
- 非阻塞同步:是一种基于冲突检查的乐观锁定策略,通常是先操作,如果没有冲突,操作就成功了,有冲突再采取其它方式进行补偿处理
- 无同步方案:其实就是再多线程中,方法并不涉及共享数据,自然也就无需同步了
锁优化:自旋锁,锁清除,锁粗化,轻量级锁,偏向锁
锁优化之自旋锁与自适应自旋
- 自旋:如果线程可以很快获得锁,那么可以不在OS层挂起线程,而是让线程做几个忙循环,这就是自旋
- 自适应自旋:自旋的时间不再固定,而是由前一次在同一个锁上的自旋时间和锁的拥有者状态来决定
- 如果锁被占用时间很短,自旋成功,那么能节省线程挂起,以及切换时间,从而提升系统性能
- 如果锁被占用时间很长,自旋失败,会白白耗费处理器资源,降低系统性能
锁优化之锁消除
- 在编译代码的时候,检测到根本不存在共享数据竞争,自然也就无需同步加锁了;通过-XX:+EliminateLocks来开启
- 同时要使用-XX:+DoEscapeAnalysis开启逃逸分析,所谓逃逸分析:
- (1)如果一个方法中定义的一个对象,可能被外部方法引用,称为方法逃逸
- (2)如果对象可能被其它外部线程访问,称为线程逃逸,比如赋值给类变量或者可以在其它线程中访问的实例变量
锁优化之锁粗化
- 通常我们都要求同步块要小,但一系列连续的操作导致对一个对象反复的加锁和解锁,这会导致不必要的性能损耗。这种情况建议把锁同步的范围加大到整个操作系列
锁优化之轻量级锁
- 轻量级是相对于传统锁机制而言,本意是没有多线程竞争的情况下,减少传统锁机制使用OS实现互斥所产生的性能损耗
- 其实现原理很简单,就是类似乐观锁的方式
- 如果轻量级锁失败,表示存在竞争,升级为重量级锁,导致性能下降
锁优化之偏向锁
- 偏向锁是在无竞争情况下,直接把整个同步消除了,连乐观锁都不用,从而提高性能;所谓的偏向,就是偏心,即锁会偏向于当前以及占有锁的线程
- 只要没有竞争,获得偏向锁的线程,在将来进入同步块,也不需要做同步
- 当有其它线程请求相同的锁时,偏向模式结束
- 如果程序中大多数锁总是被多个线程访问的时候,也就是竞争比较激烈,偏向锁反而会降低性能
- 使用-XX:-UseBiasedLocking来禁用偏向锁,默认开启
JVM中获取锁的步骤
- 会先尝试偏向锁;然后尝试轻量级锁
- 再然后尝试自旋锁
- 最后尝试普通锁,使用OS互斥量在操作系统层挂起
同步代码的基本规则
- 尽量减少锁持有的时间
- 尽量减小锁的粒度